3 Writing Functions in R
Notes taken during/inspired by the Datacamp course ‘Writing Functions in R’ by Hadley and Charlotte Wickham.
R can create functions using a basic ‘receipe’ as Hadley calls it
my_fun <- function(arg1, arg2) {
body
}Unlike in other languages, there is no special syntax for naming a function. Once created, there is no difference between the functions you create and the functions created by other developers such as those in base R.
Every function has three components
- The formal arguments
- The body of the function
- The environment - usually invisible but determines where the function looks for variables
The environemnt is where the function was defined, if just coding the function in this will be the global environment.
The output from a function is usually the last expression evaluated. However, it is possible to use a return statement to return(value) which will stop the function at that point. It is possible to have functions without a name, so called ‘anonymous’ functions, which are covered later in this chapter. Anonymous functions can be called, but have to be done on the same line.
Course slides: * Part 1 - Refresher * Part 2 - When and how you should write a function * Part 3 - Functional programming * Part 4 - Advanced inputs and outputs * Part 5 - Robust functions
Other useful info:
3.1 Function overview
# Define ratio() function
ratio <- function(x, y) {
x / y
}
# Call ratio() with arguments 3 and 4
ratio(3, 4)## [1] 0.75There are two ways to specify the arguments - ratio(3, 4), which relies on matching by position, or ratio(x = 3, y = 4), which relies on matching by name.
For functions you and others use often, it’s okay to use positional matching for the first one or two arguments. These are usually the data to be computed on. Good examples are the x argument to the summary functions (mean(), sd(), etc.) and the x and y arguments to plotting functions.
However, beyond the first couple of arguments you should always use matching by name. It makes your code much easier for you and others to read. This is particularly important if the argument is optional, because it has a default. When overriding a default value, it’s good practice to use the name.
Notice that when you call a function, you should place a space around = in function calls, and always put a space after a comma, not before (just like in regular English). Using whitespace makes it easier to skim the function for the important components.
In the follwing example we tidy up the function to follow best practice and make it easier to understand and repeat if needed in the future.
# Original
mean(0.1,x=c(1:9, NA),TRUE)## [1] 5# Rewrite the call to follow best practices
mean(c(1:9, NA), trim = 0.1, na.rm = TRUE)## [1] 53.1.1 Scoping
Scoping describes how R looks up values when given a name. When creating a function, R will look within that function first for a name e.g. x. If it doesn’t exist in that environment, it will look one level up, so if you’ve defined x but not y in a function, R will look for y in the next environment up - if within a single function, this next level up will be the gobal environment. Every time you cann a function, it will get a ‘clean’ environment.
3.1.2 Data Structures
There are two main typers of data structure in R - atomic vectors and lists (which are multiple vectors). Lists are useful because they can be used to have different data ypes within them, they have nested vectors in effect. Lists can be referenced either with a single brackedt [], a double braket [[]] which will strip out a level of hierachy or the usual dollar notation $.
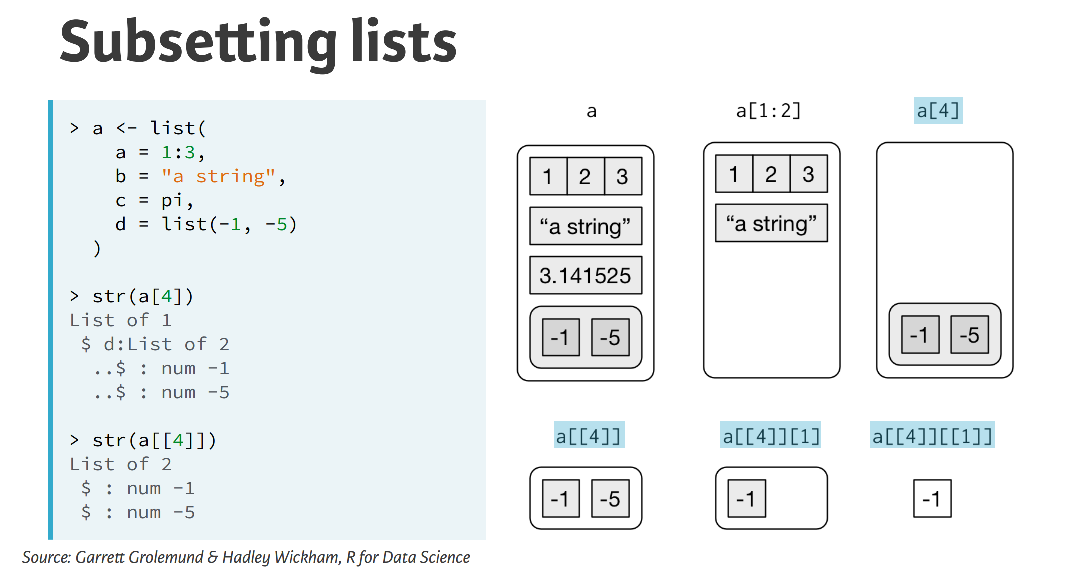
(#fig:Subsetting Lists)Subsetting List flavours
There are a few ways to subset a list. Throughout the course we’ll mostly use double bracket ([[]]) subsetting by index and by name.
That is, my_list[[1]] extracts the first element of the list my_list, and my_list[[“name”]] extracts the element in my_list that is called name. If the list is nested you can travel down the heirarchy by recursive subsetting. For example, mylist[[1]][[“name”]] is the element called name inside the first element of my_list.
A data frame is just a special kind of list, so you can use double bracket subsetting on data frames too. my_df[[1]] will extract the first column of a data frame and my_df[[“name”]] will extract the column named name from the data frame.
# 2nd element in tricky_list
typeof(tricky_list[[2]])
# Element called x in tricky_list
typeof(tricky_list[["x"]])
# 2nd element inside the element called x in tricky_list
typeof(tricky_list[["x"]][[2]])Sometimes the output of models can be quite challenging to get out, with many lists inside a single list.
# Guess where the regression model is stored
names(tricky_list)
# Use names() and str() on the model element
names(tricky_list[["model"]])
str(tricky_list[["model"]])
# Subset the coefficients element
tricky_list[["model"]][["coefficients"]]
# Subset the wt element
tricky_list[["model"]][["coefficients"]][["wt"]]3.1.3 For loops
For loops are used for iteraction. There are a number of parts within a loop:
- 1: The sequence - describes the name of an object with indexes an iteration e.g. i, and the values that this index should iterate over
- 2: The body - between the curly braces {} and describes the operations to iterate over, referring back to the index (e.g. i)
- 3: The output - where should the results of the loop go? OFten this might print to the screen rather than saving the output
If you want to repeat a function for each column where the data frame is empty, rather than use the sequence for (i in 1:ncol(df)), it is better to use seq_along(df), since our sequence is now the somewhat non-sensical: 1, 0. You might think you wouldn’t be silly enough to use a for loop with an empty data frame, but once you start writing your own functions, there’s no telling what the input will be.
df <- data.frame()
1:ncol(df)
# doesn't handle the empty data well
for (i in 1:ncol(df)) {
print(median(df[[i]]))
}
# Replace the 1:ncol(df) sequence
for (i in seq_along(df)) {
print(median(df[[i]]))
}Our for loop does a good job displaying the column medians, but we might want to store these medians in a vector for future use.
Before you start the loop, you must always allocate sufficient space for the output, let’s say an object called output. This is very important for efficiency: if you grow the for loop at each iteration (e.g. using c()), your for loop will be very slow.
A general way of creating an empty vector of given length is the vector() function. It has two arguments: the type of the vector (“logical”, “integer”, “double”, “character”, etc.) and the length of the vector.
Then, at each iteration of the loop you must store the output in the corresponding entry of the output vector, i.e. assign the result to output[[i]]. (You might ask why we are using double brackets here when output is a vector. It’s primarily for generalizability: this subsetting will work whether output is a vector or a list.)
Let’s edit our loop to store the medians, rather than printing them to the console.
# Create new double vector: output
output <- vector("double", ncol(df))
# Alter the loop
for (i in seq_along(df)) {
# Change code to store result in output
output[i] <- median(df[[i]])
}
# Print output
output3.2 When and how you should write a function
Why might you write a function? Doing the same thing many times is not efficient and it can lead to errors - you copy the same function/formula from a previous exercise, but forget to change a variable name to fit your new instance.
If you have copied and pasted twice, meaning you now have three copies, it is time to write a function
As it takes less effort to check the intent of the code - there is just one function to check - more time can be spent on checking the validity or quality of the data and outputs. In addition, since we have created a function, we can use other packages such as the map function in purrr, to repeat (map) our functions repeatadly.
3.2.1 Rescale example
We have a snippet of code that successfully rescales a column to be between 0 and 1:
(df\(a - min(df\)a, na.rm = TRUE)) /
(max(df\(a, na.rm = TRUE) - min(df\)a, na.rm = TRUE))
Our goal over the next few exercises is to turn this snippet, written to work on the a column in the data frame df, into a general purpose rescale01() function that we can apply to any vector.
The first step of turning a snippet into a function is to examine the snippet and decide how many inputs there are, then rewrite the snippet to refer to these inputs using temporary names. These inputs will become the arguments to our function, so choosing good names for them is important. (We’ll talk more about naming arguments in a later exercise.)
In this snippet, there is one input: the numeric vector to be rescaled (currently df$a). What would be a good name for this input? It’s quite common in R to refer to a vector of data simply as x (like in the mean function), so we will follow that convention here.
# Define example vector x
x <- seq(1:10)
# Rewrite this snippet to refer to x
(x - min(x, na.rm = TRUE)) /
(max(x, na.rm = TRUE) - min(x, na.rm = TRUE))## [1] 0.0000000 0.1111111 0.2222222 0.3333333 0.4444444 0.5555556 0.6666667
## [8] 0.7777778 0.8888889 1.0000000Our next step is to examine our snippet and see if we can write it more clearly.
Take a close look at our rewritten snippet. Do you see any duplication?
(x - min(x, na.rm = TRUE)) / (max(x, na.rm = TRUE) - min(x, na.rm = TRUE))
One obviously duplicated statement is min(x, na.rm = TRUE). It makes more sense for us just to calculate it once, store the result, and then refer to it when needed. In fact, since we also need the maximum value of x, it would be even better to calculate the range once, then refer to the first and second elements when they are needed.
What should we call this intermediate variable? You’ll soon get the message that using good names is an important part of writing clear code! I suggest we call it rng (for “range”).
# Define example vector x
x <- 1:10
# Define rng
rng <- range(x, na.rm = TRUE)
# Rewrite this snippet to refer to the elements of rng
(x - rng[1]) /
(rng[2] - rng[1])## [1] 0.0000000 0.1111111 0.2222222 0.3333333 0.4444444 0.5555556 0.6666667
## [8] 0.7777778 0.8888889 1.0000000What do you need to write a function? You need a name for the function, you need to know the arguments to the function, and you need code that forms the body of the function.
# Define example vector x
x <- 1:10
# Use the function template to create the rescale01 function
rescale01 <- function(x) {
# body
rng <- range(x, na.rm = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}
# Test your function, call rescale01 using the vector x as the argument
rescale01(x)## [1] 0.0000000 0.1111111 0.2222222 0.3333333 0.4444444 0.5555556 0.6666667
## [8] 0.7777778 0.8888889 1.00000003.2.2 Write a function step by step
Typically we go through a similar process in order to write a function:
- Start with a simiple problem
- Get a working snippet of code
- Rewrite the code to use temporary variables
- See if there is any duplication that we can minimise and rewrite to remove this
- With this clearly working version, we can turn it in to a function, by wrapping the code in a function
In this next section we are going to go through these steps in order to write a function - both_na() - that counts at how many positions two vectors, x and y, both have a missing value.
So first, we start writing some simple code to see how we get something workable.
# Define example vectors x and y
x <- c( 1, 2, NA, 3, NA)
y <- c(NA, 3, NA, 3, 4)
# Count how many elements are missing in both x and y
sum(is.na(x) & is.na(y))## [1] 1So the function appears to be doing what we want, the function is already quite simple so we don’t need to simplify further, so we proceed to wrap the function.
# Turn this snippet into a function: both_na()
both_na <- function(x, y) {
sum(is.na(x) & is.na(y))
}Now we can test whether the function operates as intended by using some other examples.
# Define x, y1 and y2
x <- c(NA, NA, NA)
y1 <- c( 1, NA, NA)
y2 <- c( 1, NA, NA, NA)
# Call both_na on x, y1
both_na(x, y1)## [1] 2# Call both_na on x, y2
both_na(x, y2)## Warning in is.na(x) & is.na(y): longer object length is not a multiple of
## shorter object length## [1] 33.2.3 How can you write a good function?
It should have the following criteria fulfilled
- It should be correct
- It should be understandable to other people
- Correct + understandable = obvioulsy correct
Good names can help make the data more understandable. Good naming applies to all aspects in R - objects, functions or arguments. Some examples are below, it doesn’t matter which convention you follow although it is important to stick to the approach i.e. be consistent.
- Long names - these should be lower case and seperated with underscores e.g. row_maxes
- Other names - don’t override existing variables or functions e.g. T <- FALSE or c <- 10
- Function names - use a verb as a name, since the function does something
- Argument names - use nouns or naming words
- Argument length - use short names when appropriate e.g. x,y or z
- Data frames - usually referred to as df
- Numeric indices - use i and j typically rows and columns
- Others - n for the number of rows, p for the number of columns
- Argument order - usually we placed data objects first, like x or df, then things that control the computation next (detail) which should be given default values
Also think about having an R style guide.
3.3 Functional Programming
Writing for loops in R is not best practice. They are like detailed recipe books which outline very detailed step in a recipe, they don’t rely on any pre-existing knowledge so as a consequence, become very long. This can make it hard to understand and see differences and similarities between different recipes (for loops). For loops tend to relegate the verbs by hiding them in a sea of nouns. Using functional programming allows you to create ‘meta recipes’ which helps to identify what is different and what is the same, by simplifying some of the steps.
In the following example we will create a data frame, then try to calculate a median for each column. This could be achieved by repeating median(df[[p]]) for each column p in the df, but it would be a lot of repetition. The following shows how you would use a for loop
# Create the dataframe
df <- data.frame(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
# Initialize output vector
output <- vector("double", ncol(df))
# Fill in the body of the for loop
for (i in seq_along(df)) {
output[i] <- median(df[[i]])
}
# View the result
output## [1] 0.30104359 0.07076497 -0.58144482 -0.04331344Now if we had two more data frames, df2 and df3 we would have something similar to the following
# Create the dataframe2
df2 <- data.frame(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
# Create the dataframe3
df3 <- data.frame(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
output <- vector("double", ncol(df2))
for (i in seq_along(df2)) {
output[[i]] <- median(df2[[i]])
}
output## [1] -0.0641349 0.2422641 -0.2854498 -0.2563127output <- vector("double", ncol(df3))
for (i in seq_along(df3)) {
output[[i]] <- median(df3[[i]])
}
output## [1] 0.4657658 0.1358885 -0.2084402 -0.1577409It would be easier to write a function in this instance.
# Turn this code into col_median()
col_median <- function(df) {
output <- vector("double", ncol(df))
for (i in seq_along(df)) {
output[[i]] <- median(df[[i]])
}
output
}
col_median(df2)## [1] -0.0641349 0.2422641 -0.2854498 -0.2563127col_median(df3)## [1] 0.4657658 0.1358885 -0.2084402 -0.1577409And if we wanted means instead of medians we could write a similar function.
# Create col_mean() function to find column means
col_mean <- function(df) {
output <- numeric(length(df))
for (i in seq_along(df)) {
output[[i]] <- mean(df[[i]])
}
output
}
col_mean(df2)## [1] 0.1970742 0.1477954 -0.1617852 -0.1566563col_mean(df3)## [1] 0.45339778 0.34380317 0.12075255 0.06709137And if we wanted standard deviations
# Define col_sd() function
col_sd <- function(df) {
output <- numeric(length(df))
for (i in seq_along(df)) {
output[[i]] <- sd(df[[i]])
}
output
}
col_sd(df2)## [1] 1.0386878 0.6958183 1.3089331 0.8902624col_sd(df3)## [1] 1.1144186 1.3909175 1.2245477 0.8780557We have now copied our median function twice - to create mean and sd functions. It would be writter to write a function which will take column summaries for any summary function we provide.
f <- function(x, power) {
# Edit the body to return absolute deviations raised to power
abs(x - mean(x)) ^ power
}We can also use functions as arguments, by replacing the mean or median elements with fun, where fun = the summary function desired.
col_summary <- function(df, fun) {
output <- vector("numeric", length(df))
for (i in seq_along(df)) {
output[[i]] <- fun(df[[i]])
}
output
}3.3.1 Using purrr
Passing functions as arguments is quite a common task in R, we can use the map function in purrr to achieve this. Every function in the purrr package takes a vector to begin with (.x) and loops over it to do something (.f) e.g. map_dbl(.x, .f, …). The types of map functions are:
- map() returns a list
- map_dbl() returns a double vector
- map_lgl() returns a logical vector
- map_int() returns a integer vector
- map_chr() returns a character vector
Arguments to map() are .x and .f and not x and f because .x and .f are very unlikely to be argument names you might pass through the …, thereby preventing confusion about whether an argument belongs to map() or to the function being mapped.
# load the package and examine the data
library(purrr)
library(nycflights13)## Warning: package 'nycflights13' was built under R version 3.4.2library(dplyr) # to select just the numeric columns of our dataset ##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionstr(planes)## Classes 'tbl_df', 'tbl' and 'data.frame': 3322 obs. of 9 variables:
## $ tailnum : chr "N10156" "N102UW" "N103US" "N104UW" ...
## $ year : int 2004 1998 1999 1999 2002 1999 1999 1999 1999 1999 ...
## $ type : chr "Fixed wing multi engine" "Fixed wing multi engine" "Fixed wing multi engine" "Fixed wing multi engine" ...
## $ manufacturer: chr "EMBRAER" "AIRBUS INDUSTRIE" "AIRBUS INDUSTRIE" "AIRBUS INDUSTRIE" ...
## $ model : chr "EMB-145XR" "A320-214" "A320-214" "A320-214" ...
## $ engines : int 2 2 2 2 2 2 2 2 2 2 ...
## $ seats : int 55 182 182 182 55 182 182 182 182 182 ...
## $ speed : int NA NA NA NA NA NA NA NA NA NA ...
## $ engine : chr "Turbo-fan" "Turbo-fan" "Turbo-fan" "Turbo-fan" ...planes2 <- select_if(planes, is.numeric)
# Find the mean of each column
map_dbl(planes2, mean)## year engines seats speed
## NA 1.995184 154.316376 NA# Find the mean of each column, excluding missing values
map_dbl(planes2, mean, na.rm = T)## year engines seats speed
## 2000.484010 1.995184 154.316376 236.782609# Find the 5th percentile of each column, excluding missing values
map_dbl(planes2, quantile, probs = .05, na.rm = T)## year engines seats speed
## 1988.0 2.0 55.0 90.5# Find the columns that are numeric
map_lgl(df3, is.numeric)## a b c d
## TRUE TRUE TRUE TRUE# Find the type of each column
map_chr(df3, typeof)## a b c d
## "double" "double" "double" "double"# Find a summary of each column
map(df3, summary)## $a
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -1.3180 -0.3523 0.4658 0.4534 1.4880 1.9203
##
## $b
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -1.2480 -0.5321 0.1359 0.3438 0.7812 3.5138
##
## $c
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -1.7018 -0.4845 -0.2084 0.1208 0.4456 2.7308
##
## $d
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -0.84672 -0.56942 -0.15774 0.06709 0.57799 1.870963.3.2 Shortcuts
You can define an anonymous function on the fly like
map(df, function(x) sum(is.na(x)))
Which will count how many missing values are in x. This allows you to create and map your own functions.
In the next set of exercises we will use the mtcars data, but split the dataset in to a set for each number of cylinders in the engine e.g. 4, 6 and 8 cylinders.
Our goal is to fit a separate linear regression of miles per gallon (mpg) against weight (wt) for each group of cars in our list of data frames, where each data frame in our list represents a different group. How should we get started?
First, let’s confirm the structure of this list of data frames. Then, we’ll solve a simpler problem first: fit the regression to the first group of cars.
# Split the data
cyl <- split(mtcars, mtcars$cyl)
# Examine the structure of cyl
str(cyl)## List of 3
## $ 4:'data.frame': 11 obs. of 11 variables:
## ..$ mpg : num [1:11] 22.8 24.4 22.8 32.4 30.4 33.9 21.5 27.3 26 30.4 ...
## ..$ cyl : num [1:11] 4 4 4 4 4 4 4 4 4 4 ...
## ..$ disp: num [1:11] 108 146.7 140.8 78.7 75.7 ...
## ..$ hp : num [1:11] 93 62 95 66 52 65 97 66 91 113 ...
## ..$ drat: num [1:11] 3.85 3.69 3.92 4.08 4.93 4.22 3.7 4.08 4.43 3.77 ...
## ..$ wt : num [1:11] 2.32 3.19 3.15 2.2 1.61 ...
## ..$ qsec: num [1:11] 18.6 20 22.9 19.5 18.5 ...
## ..$ vs : num [1:11] 1 1 1 1 1 1 1 1 0 1 ...
## ..$ am : num [1:11] 1 0 0 1 1 1 0 1 1 1 ...
## ..$ gear: num [1:11] 4 4 4 4 4 4 3 4 5 5 ...
## ..$ carb: num [1:11] 1 2 2 1 2 1 1 1 2 2 ...
## $ 6:'data.frame': 7 obs. of 11 variables:
## ..$ mpg : num [1:7] 21 21 21.4 18.1 19.2 17.8 19.7
## ..$ cyl : num [1:7] 6 6 6 6 6 6 6
## ..$ disp: num [1:7] 160 160 258 225 168 ...
## ..$ hp : num [1:7] 110 110 110 105 123 123 175
## ..$ drat: num [1:7] 3.9 3.9 3.08 2.76 3.92 3.92 3.62
## ..$ wt : num [1:7] 2.62 2.88 3.21 3.46 3.44 ...
## ..$ qsec: num [1:7] 16.5 17 19.4 20.2 18.3 ...
## ..$ vs : num [1:7] 0 0 1 1 1 1 0
## ..$ am : num [1:7] 1 1 0 0 0 0 1
## ..$ gear: num [1:7] 4 4 3 3 4 4 5
## ..$ carb: num [1:7] 4 4 1 1 4 4 6
## $ 8:'data.frame': 14 obs. of 11 variables:
## ..$ mpg : num [1:14] 18.7 14.3 16.4 17.3 15.2 10.4 10.4 14.7 15.5 15.2 ...
## ..$ cyl : num [1:14] 8 8 8 8 8 8 8 8 8 8 ...
## ..$ disp: num [1:14] 360 360 276 276 276 ...
## ..$ hp : num [1:14] 175 245 180 180 180 205 215 230 150 150 ...
## ..$ drat: num [1:14] 3.15 3.21 3.07 3.07 3.07 2.93 3 3.23 2.76 3.15 ...
## ..$ wt : num [1:14] 3.44 3.57 4.07 3.73 3.78 ...
## ..$ qsec: num [1:14] 17 15.8 17.4 17.6 18 ...
## ..$ vs : num [1:14] 0 0 0 0 0 0 0 0 0 0 ...
## ..$ am : num [1:14] 0 0 0 0 0 0 0 0 0 0 ...
## ..$ gear: num [1:14] 3 3 3 3 3 3 3 3 3 3 ...
## ..$ carb: num [1:14] 2 4 3 3 3 4 4 4 2 2 ...# Extract the first element into four_cyls
four_cyls <- cyl[[1]]
# Fit a linear regression of mpg on wt using four_cyls
lm(wt ~ mpg, four_cyls)##
## Call:
## lm(formula = wt ~ mpg, data = four_cyls)
##
## Coefficients:
## (Intercept) mpg
## 4.68734 -0.09007We now have a snippet of code that performs the operation we want on one data frame. One option would be to turn this into a function, for example:
fit_reg <- function(df) { lm(mpg ~ wt, data = df) }
Then pass this function into map():
map(cyl, fit_reg)
But it seems a bit much to define a function for such a specific model when we only want to do this once. Instead of defining the function in the global environment, we will just use the function anonymously inside our call to map().
What does this mean? Instead of referring to our function by name in map(), we define it on the fly in the .f argument to map()
# Rewrite to call an anonymous function
map(cyl, function(df) lm(mpg ~ wt, data = df))## $`4`
##
## Call:
## lm(formula = mpg ~ wt, data = df)
##
## Coefficients:
## (Intercept) wt
## 39.571 -5.647
##
##
## $`6`
##
## Call:
## lm(formula = mpg ~ wt, data = df)
##
## Coefficients:
## (Intercept) wt
## 28.41 -2.78
##
##
## $`8`
##
## Call:
## lm(formula = mpg ~ wt, data = df)
##
## Coefficients:
## (Intercept) wt
## 23.868 -2.192Writing anonymous functions takes a lot of extra key strokes, so purrr provides a shortcut that allows you to write an anonymous function as a one-sided formula instead.
In R, a one-sided formula starts with a ~, followed by an R expression. In purrr’s map functions, the R expression can refer to an element of the .x argument using the . character.
Let’s take a look at an example. Imagine, instead of a regression on each data frame in cyl, we wanted to know the mean displacement for each data frame. One way to do this would be to use an anonymous function:
map_dbl(cyl, function(df) mean(df$disp))
To perform the same operation using the formula shortcut, we replace the function definition (function(df)) with the ~, then when we need to refer to the element of cyl the function operates on (in this case df), we use a ..
map_dbl(cyl, ~ mean(.$disp))
Much less typing. It also saves you from coming up with an argument name. Lets rewrite our previous anonymous function using this formula shortcut instead.
# Rewrite to use the formula shortcut instead
map(cyl, ~ lm(mpg ~ wt, data = .))## $`4`
##
## Call:
## lm(formula = mpg ~ wt, data = .)
##
## Coefficients:
## (Intercept) wt
## 39.571 -5.647
##
##
## $`6`
##
## Call:
## lm(formula = mpg ~ wt, data = .)
##
## Coefficients:
## (Intercept) wt
## 28.41 -2.78
##
##
## $`8`
##
## Call:
## lm(formula = mpg ~ wt, data = .)
##
## Coefficients:
## (Intercept) wt
## 23.868 -2.192There are also some useful shortcuts that come in handy when you want to subset each element of the .x argument. If the .f argument to a map function is set equal to a string, let’s say “name”, then purrr extracts the “name” element from every element of .x.
This is a really common situation you find yourself in when you work with nested lists. For example, if we have a list of where every element contains an a and b element:
list_of_results <- list( list(a = 1, b = “A”), list(a = 2, b = “C”), list(a = 3, b = “D”) )
We might want to pull out the a element from every entry. We could do it with the string shortcut like this:
map(list_of_results, “a”)
Now take our list of regresssion models:
map(cyl, ~ lm(mpg ~ wt, data = .))
It might be nice to extract the slope coefficient from each model. You’ll do this in a few steps: first fit the models, then get the coefficients from each model using the coef() function, then pull out the wt estimate using the string shortcut.
# Save the result from the previous exercise to the variable models
models <- map(cyl, ~ lm(mpg ~ wt, data = .))
# Use map and coef to get the coefficients for each model: coefs
coefs <- map(models, ~ coef(.))
# Use string shortcut to extract the wt coefficient
map(coefs, "wt")## $`4`
## [1] -5.647025
##
## $`6`
## [1] -2.780106
##
## $`8`
## [1] -2.192438Another useful shortcut for subsetting is to pass a numeric vector as the .f argument. This works just like passing a string but subsets by index rather than name. For example, with your previous list_of_results:
list_of_results <- list( list(a = 1, b = “A”), list(a = 2, b = “C”), list(a = 3, b = “D”) )
Another way to pull out the a element from each list, is to pull out the first element:
map(list_of_results, 1)
Let’s pull out the slopes from our models again, but this time using numeric subsetting. Also, since we are pulling out a single numeric value from each element, let’s use map_dbl().
# use map_dbl with the numeric shortcut to pull out the second element
map_dbl(coefs, 1)## 4 6 8
## 39.57120 28.40884 23.86803purrr also includes a pipe operator: %>%. The pipe operator is another shortcut that saves typing, but also increases readability. The example below pulls out the R2 from each model. Rewrite the last two lines to use a pipe instead.
# Define models (don't change)
models <- mtcars %>%
split(mtcars$cyl) %>%
map(~ lm(mpg ~ wt, data = .))
# Original code
# summaries <- map(models, summary)
# map_dbl(summaries, "r.squared")
# Re-writen to single command with pipes
models %>%
map(summary) %>%
map_dbl("r.squared")## 4 6 8
## 0.5086326 0.4645102 0.42296553.4 Advanced Inputs and Outputs
When using purrr, problems like errors with a single item within the map function, for instance char instead of numeric data in a list of lists, can cause errors with all the map functions. We don’t know which element caused the error and we cant access any of the succesful runs. Purrr comes with a function called safely, which will return both successful elements and errors. It will take a function and return a variaton of that function which will never give an error - it will return two results, those successful (result) and those not (errors). This is one adverb for dealing with unusual output:
- safely() captures the successful result or the error, always returns a list
- possibly() always succeeds, you give it a default value to return when there is an error
- quietly() captures printed output, messages, and warnings instead of capturing errors
# Create safe_readLines() by passing readLines() to safely()
safe_readLines <- safely(readLines)
# Call safe_readLines() on "http://example.org"
safe_readLines("http://example.org")## $result
## [1] "<!doctype html>"
## [2] "<html>"
## [3] "<head>"
## [4] " <title>Example Domain</title>"
## [5] ""
## [6] " <meta charset=\"utf-8\" />"
## [7] " <meta http-equiv=\"Content-type\" content=\"text/html; charset=utf-8\" />"
## [8] " <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\" />"
## [9] " <style type=\"text/css\">"
## [10] " body {"
## [11] " background-color: #f0f0f2;"
## [12] " margin: 0;"
## [13] " padding: 0;"
## [14] " font-family: \"Open Sans\", \"Helvetica Neue\", Helvetica, Arial, sans-serif;"
## [15] " "
## [16] " }"
## [17] " div {"
## [18] " width: 600px;"
## [19] " margin: 5em auto;"
## [20] " padding: 50px;"
## [21] " background-color: #fff;"
## [22] " border-radius: 1em;"
## [23] " }"
## [24] " a:link, a:visited {"
## [25] " color: #38488f;"
## [26] " text-decoration: none;"
## [27] " }"
## [28] " @media (max-width: 700px) {"
## [29] " body {"
## [30] " background-color: #fff;"
## [31] " }"
## [32] " div {"
## [33] " width: auto;"
## [34] " margin: 0 auto;"
## [35] " border-radius: 0;"
## [36] " padding: 1em;"
## [37] " }"
## [38] " }"
## [39] " </style> "
## [40] "</head>"
## [41] ""
## [42] "<body>"
## [43] "<div>"
## [44] " <h1>Example Domain</h1>"
## [45] " <p>This domain is established to be used for illustrative examples in documents. You may use this"
## [46] " domain in examples without prior coordination or asking for permission.</p>"
## [47] " <p><a href=\"http://www.iana.org/domains/example\">More information...</a></p>"
## [48] "</div>"
## [49] "</body>"
## [50] "</html>"
##
## $error
## NULL# Call safe_readLines() on "http://asdfasdasdkfjlda"
safe_readLines("http://asdfasdasdkfjlda")## Warning in file(con, "r"): InternetOpenUrl failed: 'The server name or
## address could not be resolved'## $result
## NULL
##
## $error
## <simpleError in file(con, "r"): cannot open the connection>Safely also works with map functions.
# Define safe_readLines()
safe_readLines <- safely(readLines)
urls <- list(
example = "http://example.org",
rproj = "http://www.r-project.org",
asdf = "http://asdfasdasdkfjlda"
)
# Use the safe_readLines() function with map(): html
html <- map(urls, safe_readLines)## Warning in file(con, "r"): InternetOpenUrl failed: 'The server name or
## address could not be resolved'# Call str() on html
str(html)## List of 3
## $ example:List of 2
## ..$ result: chr [1:50] "<!doctype html>" "<html>" "<head>" " <title>Example Domain</title>" ...
## ..$ error : NULL
## $ rproj :List of 2
## ..$ result: chr [1:122] "<!DOCTYPE html>" "<html lang=\"en\">" " <head>" " <meta charset=\"utf-8\">" ...
## ..$ error : NULL
## $ asdf :List of 2
## ..$ result: NULL
## ..$ error :List of 2
## .. ..$ message: chr "cannot open the connection"
## .. ..$ call : language file(con, "r")
## .. ..- attr(*, "class")= chr [1:3] "simpleError" "error" "condition"# Extract the result from one of the successful elements
html[[1]]## $result
## [1] "<!doctype html>"
## [2] "<html>"
## [3] "<head>"
## [4] " <title>Example Domain</title>"
## [5] ""
## [6] " <meta charset=\"utf-8\" />"
## [7] " <meta http-equiv=\"Content-type\" content=\"text/html; charset=utf-8\" />"
## [8] " <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\" />"
## [9] " <style type=\"text/css\">"
## [10] " body {"
## [11] " background-color: #f0f0f2;"
## [12] " margin: 0;"
## [13] " padding: 0;"
## [14] " font-family: \"Open Sans\", \"Helvetica Neue\", Helvetica, Arial, sans-serif;"
## [15] " "
## [16] " }"
## [17] " div {"
## [18] " width: 600px;"
## [19] " margin: 5em auto;"
## [20] " padding: 50px;"
## [21] " background-color: #fff;"
## [22] " border-radius: 1em;"
## [23] " }"
## [24] " a:link, a:visited {"
## [25] " color: #38488f;"
## [26] " text-decoration: none;"
## [27] " }"
## [28] " @media (max-width: 700px) {"
## [29] " body {"
## [30] " background-color: #fff;"
## [31] " }"
## [32] " div {"
## [33] " width: auto;"
## [34] " margin: 0 auto;"
## [35] " border-radius: 0;"
## [36] " padding: 1em;"
## [37] " }"
## [38] " }"
## [39] " </style> "
## [40] "</head>"
## [41] ""
## [42] "<body>"
## [43] "<div>"
## [44] " <h1>Example Domain</h1>"
## [45] " <p>This domain is established to be used for illustrative examples in documents. You may use this"
## [46] " domain in examples without prior coordination or asking for permission.</p>"
## [47] " <p><a href=\"http://www.iana.org/domains/example\">More information...</a></p>"
## [48] "</div>"
## [49] "</body>"
## [50] "</html>"
##
## $error
## NULL# Extract the error from the element that was unsuccessful
html[[3]]## $result
## NULL
##
## $error
## <simpleError in file(con, "r"): cannot open the connection>We now have output that contains the HTML for each of the two URLs on which readLines() was successful and the error for the other. But the output isn’t that easy to work with, since the results and errors are buried in the inner-most level of the list.
purrr provides a function transpose() that reshapes a list so the inner-most level becomes the outer-most level. In otherwords, it turns a list-of-lists “inside-out”. Consider the following list:
nested_list <- list( x1 = list(a = 1, b = 2), x2 = list(a = 3, b = 4) )
If I need to extract the a element in x1, I could do nested_list[[“x1”]][[“a”]]. However, if I transpose the list first, the order of subsetting reverses. That is, to extract the same element I could also do transpose(nested_list)[[“a”]][[“x1”]].
This is really handy for safe output, since we can grab all the results or all the errors really easily.
# Define save_readLines() and html
safe_readLines <- safely(readLines)
html <- map(urls, safe_readLines)## Warning in file(con, "r"): InternetOpenUrl failed: 'The server name or
## address could not be resolved'# Examine the structure of transpose(html)
str(transpose(html))## List of 2
## $ result:List of 3
## ..$ example: chr [1:50] "<!doctype html>" "<html>" "<head>" " <title>Example Domain</title>" ...
## ..$ rproj : chr [1:122] "<!DOCTYPE html>" "<html lang=\"en\">" " <head>" " <meta charset=\"utf-8\">" ...
## ..$ asdf : NULL
## $ error :List of 3
## ..$ example: NULL
## ..$ rproj : NULL
## ..$ asdf :List of 2
## .. ..$ message: chr "cannot open the connection"
## .. ..$ call : language file(con, "r")
## .. ..- attr(*, "class")= chr [1:3] "simpleError" "error" "condition"# Extract the results: res
res <- transpose(html)[["result"]]
# Extract the errors: errs
errs <- transpose(html)[["error"]]What you do with the errors and results is up to you. But, commonly you’ll want to collect all the results for the elements that were successful and examine the inputs for all those that weren’t.
# Initialize some objects
safe_readLines <- safely(readLines)
html <- map(urls, safe_readLines)## Warning in file(con, "r"): InternetOpenUrl failed: 'The server name or
## address could not be resolved'res <- transpose(html)[["result"]]
errs <- transpose(html)[["error"]]
# Create a logical vector is_ok
is_ok <- map_lgl(errs, is_null)
# Extract the successful results
res[is_ok]## $example
## [1] "<!doctype html>"
## [2] "<html>"
## [3] "<head>"
## [4] " <title>Example Domain</title>"
## [5] ""
## [6] " <meta charset=\"utf-8\" />"
## [7] " <meta http-equiv=\"Content-type\" content=\"text/html; charset=utf-8\" />"
## [8] " <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\" />"
## [9] " <style type=\"text/css\">"
## [10] " body {"
## [11] " background-color: #f0f0f2;"
## [12] " margin: 0;"
## [13] " padding: 0;"
## [14] " font-family: \"Open Sans\", \"Helvetica Neue\", Helvetica, Arial, sans-serif;"
## [15] " "
## [16] " }"
## [17] " div {"
## [18] " width: 600px;"
## [19] " margin: 5em auto;"
## [20] " padding: 50px;"
## [21] " background-color: #fff;"
## [22] " border-radius: 1em;"
## [23] " }"
## [24] " a:link, a:visited {"
## [25] " color: #38488f;"
## [26] " text-decoration: none;"
## [27] " }"
## [28] " @media (max-width: 700px) {"
## [29] " body {"
## [30] " background-color: #fff;"
## [31] " }"
## [32] " div {"
## [33] " width: auto;"
## [34] " margin: 0 auto;"
## [35] " border-radius: 0;"
## [36] " padding: 1em;"
## [37] " }"
## [38] " }"
## [39] " </style> "
## [40] "</head>"
## [41] ""
## [42] "<body>"
## [43] "<div>"
## [44] " <h1>Example Domain</h1>"
## [45] " <p>This domain is established to be used for illustrative examples in documents. You may use this"
## [46] " domain in examples without prior coordination or asking for permission.</p>"
## [47] " <p><a href=\"http://www.iana.org/domains/example\">More information...</a></p>"
## [48] "</div>"
## [49] "</body>"
## [50] "</html>"
##
## $rproj
## [1] "<!DOCTYPE html>"
## [2] "<html lang=\"en\">"
## [3] " <head>"
## [4] " <meta charset=\"utf-8\">"
## [5] " <meta http-equiv=\"X-UA-Compatible\" content=\"IE=edge\">"
## [6] " <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">"
## [7] " <title>R: The R Project for Statistical Computing</title>"
## [8] ""
## [9] " <link rel=\"icon\" type=\"image/png\" href=\"/favicon-32x32.png\" sizes=\"32x32\" />"
## [10] " <link rel=\"icon\" type=\"image/png\" href=\"/favicon-16x16.png\" sizes=\"16x16\" />"
## [11] ""
## [12] " <!-- Bootstrap -->"
## [13] " <link href=\"/css/bootstrap.min.css\" rel=\"stylesheet\">"
## [14] " <link href=\"/css/R.css\" rel=\"stylesheet\">"
## [15] ""
## [16] " <!-- HTML5 shim and Respond.js for IE8 support of HTML5 elements and media queries -->"
## [17] " <!-- WARNING: Respond.js doesn't work if you view the page via file:// -->"
## [18] " <!--[if lt IE 9]>"
## [19] " <script src=\"https://oss.maxcdn.com/html5shiv/3.7.2/html5shiv.min.js\"></script>"
## [20] " <script src=\"https://oss.maxcdn.com/respond/1.4.2/respond.min.js\"></script>"
## [21] " <![endif]-->"
## [22] " </head>"
## [23] " <body>"
## [24] " <div class=\"container page\">"
## [25] " <div class=\"row\">"
## [26] " <div class=\"col-xs-12 col-sm-offset-1 col-sm-2 sidebar\" role=\"navigation\">"
## [27] "<div class=\"row\">"
## [28] "<div class=\"col-xs-6 col-sm-12\">"
## [29] "<p><a href=\"/\"><img src=\"/Rlogo.png\" width=\"100\" height=\"78\" alt = \"R\" /></a></p>"
## [30] "<p><small><a href=\"/\">[Home]</a></small></p>"
## [31] "<h2 id=\"download\">Download</h2>"
## [32] "<p><a href=\"http://cran.r-project.org/mirrors.html\">CRAN</a></p>"
## [33] "<h2 id=\"r-project\">R Project</h2>"
## [34] "<ul>"
## [35] "<li><a href=\"/about.html\">About R</a></li>"
## [36] "<li><a href=\"/logo/\">Logo</a></li>"
## [37] "<li><a href=\"/contributors.html\">Contributors</a></li>"
## [38] "<li><a href=\"/news.html\">Whatâs New?</a></li>"
## [39] "<li><a href=\"/bugs.html\">Reporting Bugs</a></li>"
## [40] "<li><a href=\"http://developer.R-project.org\">Development Site</a></li>"
## [41] "<li><a href=\"/conferences.html\">Conferences</a></li>"
## [42] "<li><a href=\"/search.html\">Search</a></li>"
## [43] "</ul>"
## [44] "</div>"
## [45] "<div class=\"col-xs-6 col-sm-12\">"
## [46] "<h2 id=\"r-foundation\">R Foundation</h2>"
## [47] "<ul>"
## [48] "<li><a href=\"/foundation/\">Foundation</a></li>"
## [49] "<li><a href=\"/foundation/board.html\">Board</a></li>"
## [50] "<li><a href=\"/foundation/members.html\">Members</a></li>"
## [51] "<li><a href=\"/foundation/donors.html\">Donors</a></li>"
## [52] "<li><a href=\"/foundation/donations.html\">Donate</a></li>"
## [53] "</ul>"
## [54] "<h2 id=\"help-with-r\">Help With R</h2>"
## [55] "<ul>"
## [56] "<li><a href=\"/help.html\">Getting Help</a></li>"
## [57] "</ul>"
## [58] "<h2 id=\"documentation\">Documentation</h2>"
## [59] "<ul>"
## [60] "<li><a href=\"http://cran.r-project.org/manuals.html\">Manuals</a></li>"
## [61] "<li><a href=\"http://cran.r-project.org/faqs.html\">FAQs</a></li>"
## [62] "<li><a href=\"http://journal.r-project.org\">The R Journal</a></li>"
## [63] "<li><a href=\"/doc/bib/R-books.html\">Books</a></li>"
## [64] "<li><a href=\"/certification.html\">Certification</a></li>"
## [65] "<li><a href=\"/other-docs.html\">Other</a></li>"
## [66] "</ul>"
## [67] "<h2 id=\"links\">Links</h2>"
## [68] "<ul>"
## [69] "<li><a href=\"http://www.bioconductor.org\">Bioconductor</a></li>"
## [70] "<li><a href=\"/other-projects.html\">Related Projects</a></li>"
## [71] "<li><a href=\"/gsoc.html\">GSoC</a></li>"
## [72] "</ul>"
## [73] "</div>"
## [74] "</div>"
## [75] " </div>"
## [76] " <div class=\"col-xs-12 col-sm-7\">"
## [77] " <h1>The R Project for Statistical Computing</h1>"
## [78] "<h2 id=\"getting-started\">Getting Started</h2>"
## [79] "<p>R is a free software environment for statistical computing and graphics. It compiles and runs on a wide variety of UNIX platforms, Windows and MacOS. To <strong><a href=\"http://cran.r-project.org/mirrors.html\">download R</a></strong>, please choose your preferred <a href=\"http://cran.r-project.org/mirrors.html\">CRAN mirror</a>.</p>"
## [80] "<p>If you have questions about R like how to download and install the software, or what the license terms are, please read our <a href=\"http://cran.R-project.org/faqs.html\">answers to frequently asked questions</a> before you send an email.</p>"
## [81] "<h2 id=\"news\">News</h2>"
## [82] "<ul>"
## [83] "<li><p><a href=\"http://cran.r-project.org/src/base-prerelease\"><strong>R version 3.4.3 (Kite-Eating Tree) prerelease versions</strong></a> will appear starting Monday 2017-11-20. Final release is scheduled for Thursday 2017-11-30.</p></li>"
## [84] "<li><p><a href=\"http://cran.r-project.org/src/base/R-3\"><strong>R version 3.4.2 (Short Summer)</strong></a> has been released on Thursday 2017-09-28.</p></li>"
## [85] "<li><p><a href=\"https://journal.r-project.org/archive/2017-1\"><strong>The R Journal Volume 9/1</strong></a> is available.</p></li>"
## [86] "<li><p><a href=\"http://cran.r-project.org/src/base/R-3\"><strong>R version 3.3.3 (Another Canoe)</strong></a> has been released on Monday 2017-03-06.</p></li>"
## [87] "<li><p><a href=\"https://journal.r-project.org/archive/2016-2\"><strong>The R Journal Volume 8/2</strong></a> is available.</p></li>"
## [88] "<li><p><strong>useR! 2017</strong> (July 4 - 7 in Brussels) has opened registration and more at http://user2017.brussels/</p></li>"
## [89] "<li><p>Tomas Kalibera has joined the R core team.</p></li>"
## [90] "<li><p>The R Foundation welcomes five new ordinary members: Jennifer Bryan, Dianne Cook, Julie Josse, Tomas Kalibera, and Balasubramanian Narasimhan.</p></li>"
## [91] "<li><p><a href=\"http://journal.r-project.org\"><strong>The R Journal Volume 8/1</strong></a> is available.</p></li>"
## [92] "<li><p>The <strong>useR! 2017</strong> conference will take place in Brussels, July 4 - 7, 2017.</p></li>"
## [93] "<li><p><a href=\"http://cran.r-project.org/src/base/R-3\"><strong>R version 3.2.5 (Very, Very Secure Dishes)</strong></a> has been released on 2016-04-14. This is a rebadging of the quick-fix release 3.2.4-revised.</p></li>"
## [94] "<li><p><strong>Notice XQuartz users (Mac OS X)</strong> A security issue has been detected with the Sparkle update mechanism used by XQuartz. Avoid updating over insecure channels.</p></li>"
## [95] "<li><p>The <a href=\"http://www.r-project.org/logo\"><strong>R Logo</strong></a> is available for download in high-resolution PNG or SVG formats.</p></li>"
## [96] "<li><p><strong><a href=\"http://www.r-project.org/useR-2016\">useR! 2016</a></strong>, has taken place at Stanford University, CA, USA, June 27 - June 30, 2016.</p></li>"
## [97] "<li><p><a href=\"http://journal.r-project.org\"><strong>The R Journal Volume 7/2</strong></a> is available.</p></li>"
## [98] "<li><p><a href=\"http://cran.r-project.org/src/base/R-3\"><strong>R version 3.2.3 (Wooden Christmas-Tree)</strong></a> has been released on 2015-12-10.</p></li>"
## [99] "<li><p><a href=\"http://cran.r-project.org/src/base/R-3\"><strong>R version 3.1.3 (Smooth Sidewalk)</strong></a> has been released on 2015-03-09.</p></li>"
## [100] "</ul>"
## [101] "<!--- (Boilerplate for release run-in)"
## [102] "- [**R version 3.1.3 (Smooth Sidewalk) prerelease versions**](http://cran.r-project.org/src/base-prerelease) will appear starting February 28. Final release is scheduled for 2015-03-09."
## [103] "-->"
## [104] " </div>"
## [105] " </div>"
## [106] " <div class=\"raw footer\">"
## [107] " © The R Foundation. For queries about this web site, please contact"
## [108] "\t<script type='text/javascript'>"
## [109] "<!--"
## [110] "var s=\"=b!isfg>#nbjmup;xfcnbtufsAs.qspkfdu/psh#?uif!xfcnbtufs=0b?\";"
## [111] "m=\"\"; for (i=0; i<s.length; i++) {if(s.charCodeAt(i) == 28){m+= '&';} else if (s.charCodeAt(i) == 23) {m+= '!';} else {m+=String.fromCharCode(s.charCodeAt(i)-1);}}document.write(m);//-->"
## [112] "\t</script>;"
## [113] " for queries about R itself, please consult the "
## [114] " <a href=\"help.html\">Getting Help</a> section."
## [115] " </div>"
## [116] " </div>"
## [117] " <!-- jQuery (necessary for Bootstrap's JavaScript plugins) -->"
## [118] " <script src=\"https://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js\"></script>"
## [119] " <!-- Include all compiled plugins (below), or include individual files as needed -->"
## [120] " <script src=\"/js/bootstrap.min.js\"></script>"
## [121] " </body>"
## [122] "</html>"# Extract the input from the unsuccessful results
urls[!is_ok]## $asdf
## [1] "http://asdfasdasdkfjlda"3.4.1 Maps over multiple arguments
If we want to add multiple arguments - for instance creating a normal distribution using rnorm() with two arguments, one for the number of rows (n) and one for the desired mean - we can use the map2 function which now takes the form
map2(.x, .y, .f …) # iterate over two arguments
But if we wanted to extend this, by adding saying the standard deviation (sd) rather than use map3 and so on for more arguments, purr has a pmap function that takes lists as inputs
pmap(.l, .f, …) # iterate over many arguments
Or if we wanted to do a similar exercise but use different functions, say to run distributions for expontial as well as rnorm, we use the invoke map() functions
invoke_map(.f, .x = list(NULL), …) # iterate over functions and arguments
This next section will use the random number generator rnorm().
# Create a list n containing the values: 5, 10, and 20
n <- list(5, 10, 20)
# Call map() on n with rnorm() to simulate three samples
map(n, rnorm)## [[1]]
## [1] -0.4366686 1.4324114 -1.5956013 -1.1505808 0.2122502
##
## [[2]]
## [1] 0.3243319 -0.9960460 -0.7376161 0.3113217 -0.2849793 -0.2588673
## [7] -0.3798126 -0.9622933 2.3591024 -1.3414916
##
## [[3]]
## [1] 2.0575641 -0.2063629 1.5997894 -0.9344443 -1.0462768 0.4878357
## [7] 1.2556464 1.4165219 -0.8103948 -1.1889049 0.9819992 -0.1521257
## [13] 1.3140112 1.2322927 -1.0607637 -0.3193866 0.1884801 0.3432868
## [19] 0.8239909 -0.8821097If we also want to vary the mean, the mean can be specified in rnorm() by the argument mean. Now there are two arguments to rnorm() we want to vary: n and mean.
The map2() function is designed exactly for this purpose; it allows iteration over two objects. The first two arguments to map2() are the objects to iterate over and the third argument .f is the function to apply.
Let’s use map2() to simulate three samples with different sample sizes and different means.
# Initialize n
n <- list(5, 10, 20)
# Create a list mu containing the values: 1, 5, and 10
mu <- list(1, 5, 10)
# Edit to call map2() on n and mu with rnorm() to simulate three samples
map2(n, mu, rnorm)## [[1]]
## [1] 1.720083 1.656689 0.798450 2.075659 -1.213459
##
## [[2]]
## [1] 6.059364 4.866746 5.195483 5.948219 5.237326 5.880230 5.762817
## [8] 2.770638 4.808516 5.295286
##
## [[3]]
## [1] 11.466687 10.622913 9.661050 9.517950 9.780029 8.685184 12.568060
## [8] 11.306317 9.724562 11.219939 9.858983 9.636000 9.934999 10.446160
## [15] 9.322075 8.903951 11.063303 10.899909 9.619289 10.003181We might want to vary: sd, the standard deviation of the Normal distribution. You might think there is a map3() function, but there isn’t. Instead purrr provides a pmap() function that iterates over 2 or more arguments.
First, let’s take a look at pmap() for the situation we just solved: iterating over two arguments. Instead of providing each item to iterate over as arguments, pmap() takes a list of arguments as its input. For example, we could replicate our previous example, iterating over both n and mu with the following:
n <- list(5, 10, 20) mu <- list(1, 5, 10)
pmap(list(n, mu), rnorm)
Notice how we had to put our two items to iterate over (n and mu) into a list.
Let’s expand this code to iterate over varying standard deviations too.
# Initialize n and mu
n <- list(5, 10, 20)
mu <- list(1, 5, 10)
# Create a sd list with the values: 0.1, 1 and 0.1
sd <- list(0.1, 1, 0.1)
# Edit this call to pmap() to iterate over the sd list as well
pmap(list(n, mu, sd), rnorm)## [[1]]
## [1] 0.8698591 1.0009957 0.9710751 0.9496946 1.0495229
##
## [[2]]
## [1] 6.472870 5.854239 4.528828 4.874714 4.466589 6.146899 4.184024
## [8] 2.707230 4.097509 6.853301
##
## [[3]]
## [1] 10.296885 10.152149 9.871139 10.070173 10.187305 10.126474 10.100678
## [8] 9.930911 10.030108 9.962779 10.104376 10.128644 9.952670 10.190224
## [15] 9.992032 9.890755 9.976874 10.139623 9.957864 10.028125By default pmap() matches the elements of the list to the arguments in the function by position.
Instead of relying on this positional matching, a safer alternative is to provide names in our list. The name of each element should be the argument name we want to match it to.
# Name the elements so they are read correctly
pmap(list(mean = mu, n = n , sd = sd), rnorm)## [[1]]
## [1] 0.9576075 0.9636535 1.0238025 1.0513216 1.2082554
##
## [[2]]
## [1] 3.185946 6.555173 5.636418 4.991143 6.161679 4.698976 4.847455
## [8] 5.882055 4.035050 5.180936
##
## [[3]]
## [1] 10.185981 10.095582 10.090515 10.070867 9.965686 9.851724 9.991329
## [8] 9.780453 10.113041 10.093998 10.227955 9.987986 10.035544 9.980724
## [15] 9.989603 9.911811 9.943535 9.954504 9.944317 9.955925Sometimes it’s not the arguments to a function you want to iterate over, but a set of functions themselves. Imagine that instead of varying the parameters to rnorm() we want to simulate from different distributions, say, using rnorm(), runif(), and rexp(). How do we iterate over calling these functions?
In purrr, this is handled by the invoke_map() function. The first argument is a list of functions. In our example, something like:
f <- list(“rnorm”, “runif”, “rexp”)
The second argument specifies the arguments to the functions. In the simplest case, all the functions take the same argument, and we can specify it directly, relying on … to pass it to each function. In this case, call each function with the argument n = 5:
invoke_map(f, n = 5)
In more complicated cases, the functions may take different arguments, or we may want to pass different values to each function. In this case, we need to supply invoke_map() with a list, where each element specifies the arguments to the corresponding function.
# Define list of functions
f <- list("rnorm", "runif", "rexp")
# Parameter list for rnorm()
rnorm_params <- list(mean = 10)
# Add a min element with value 0 and max element with value 5
runif_params <- list(min =0, max = 5)
# Add a rate element with value 5
rexp_params <- list(rate = 5)
# Define params for each function
params <- list(
rnorm_params,
runif_params,
rexp_params
)
# Call invoke_map() on f supplying params as the second argument
invoke_map(f, params, n = 5)## [[1]]
## [1] 10.443370 8.959307 10.637096 10.571040 9.406870
##
## [[2]]
## [1] 1.4220193 2.9846494 0.9510743 4.6481254 4.5609494
##
## [[3]]
## [1] 0.32896695 0.36738067 0.06013094 0.12338600 0.113877003.4.2 Side effect functions
In R we have functions that are so called ‘side effect’ functions, for example saving files or producing plots. They don’t manipulate data per se. In purrr we have a function, walk(), which is designed for use with these side effect functions rather than map(). You can also walk over 2 or more functions, like map 2 and pmap we saw earlier. Walk can be used in pipe operations also.
First, let’s check that our simulated samples are in fact what we think they are by plotting a histogram for each one.
# Define list of functions
f <- list(Normal = "rnorm", Uniform = "runif", Exp = "rexp")
# Define params
params <- list(
Normal = list(mean = 10),
Uniform = list(min = 0, max = 5),
Exp = list(rate = 5)
)
# Assign the simulated samples to sims
sims <- invoke_map(f, params, n = 50)
# Use walk() to make a histogram of each element in sims
walk(sims, hist)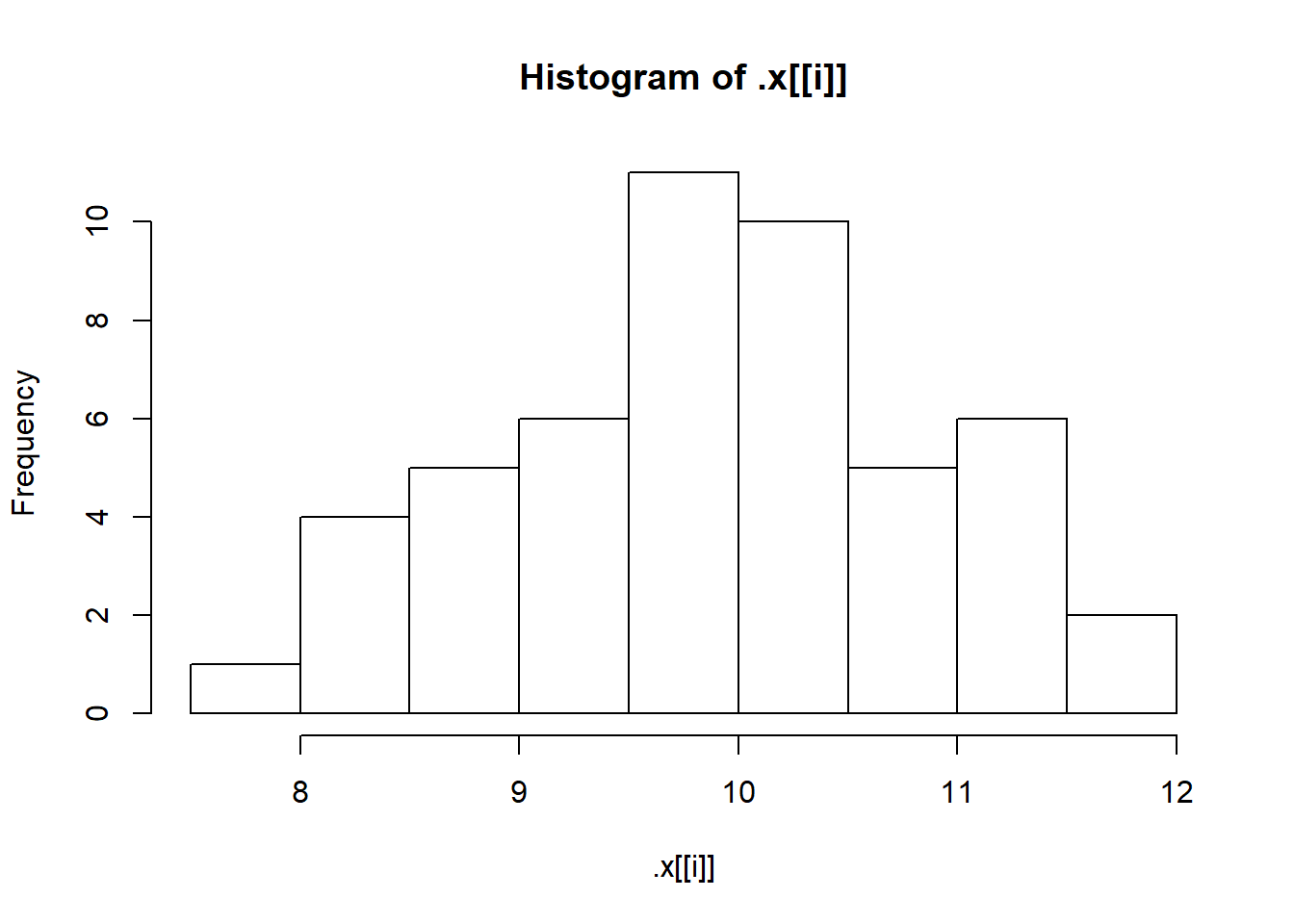
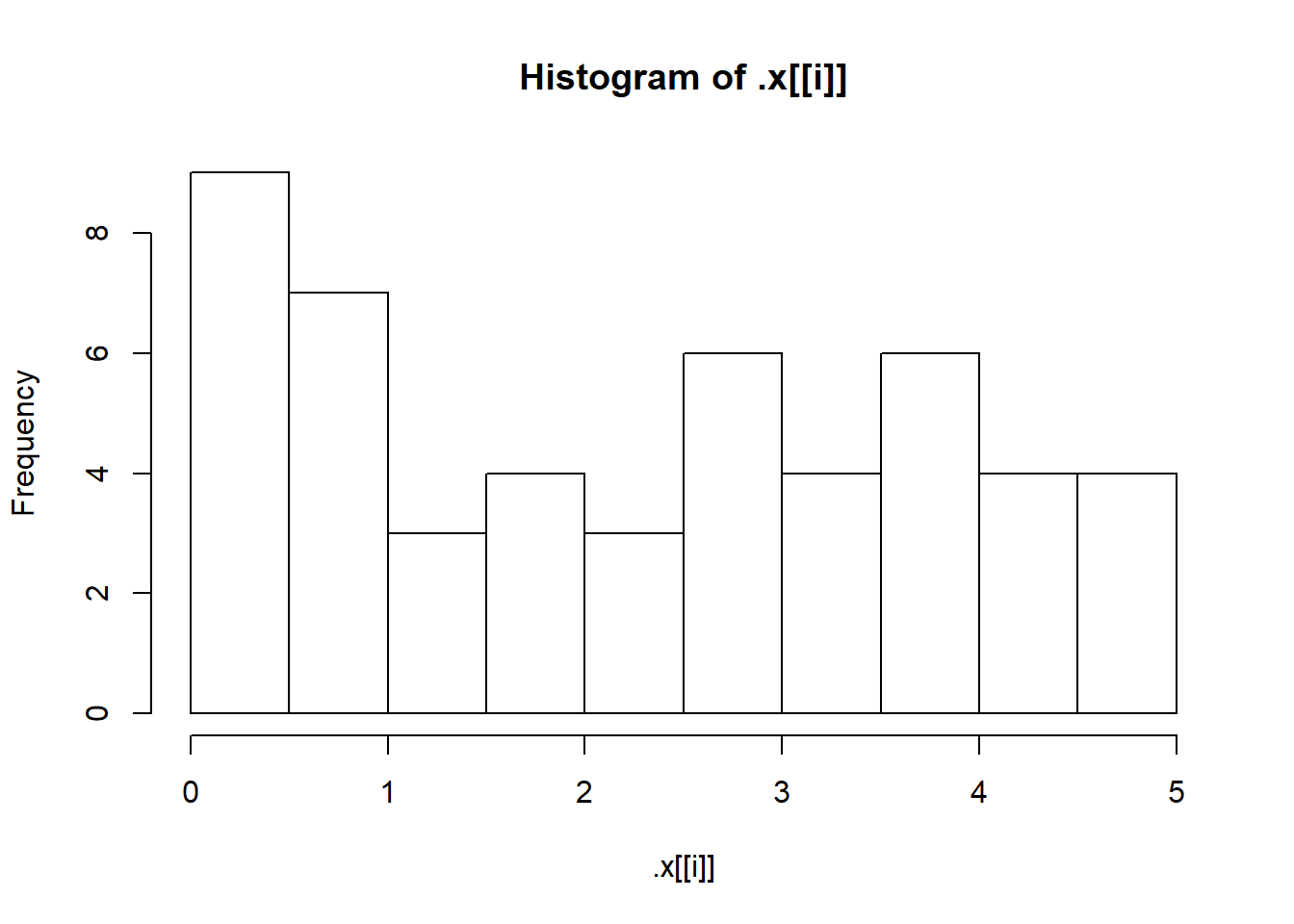
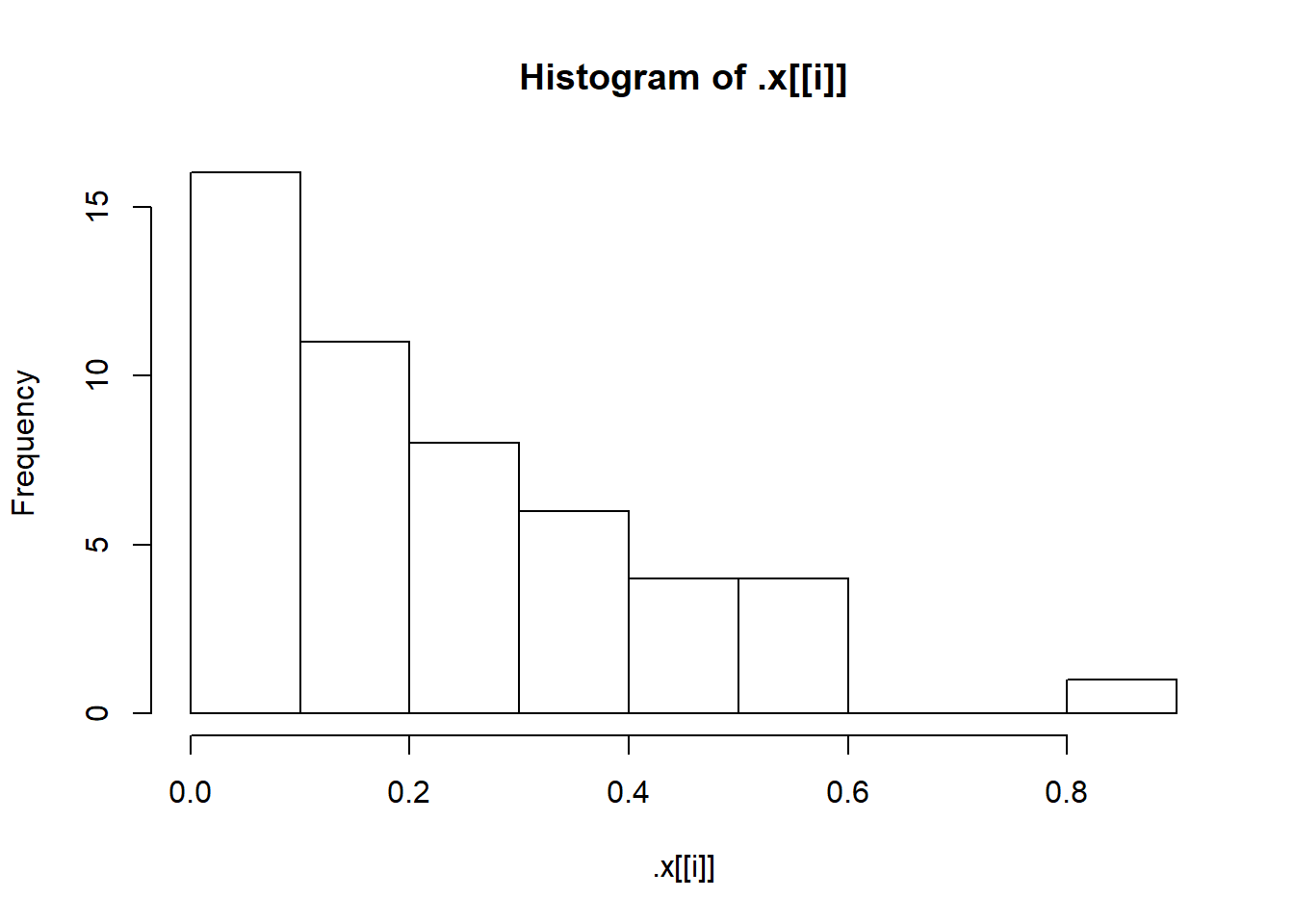
We need better breaks for the bins on the x-axis. That means we need to vary two arguments to hist(): x and breaks. Remember map2()? That allowed us to iterate over two arguments. Guess what? There is a walk2(), too! Let’s use walk2() to improve those histograms with better breaks.
# Replace "Sturges" with reasonable breaks for each sample
breaks_list <- list(
Normal = seq(6, 16, 0.5),
Uniform = seq(0, 5, 0.25),
Exp = seq(0, 1.5, 0.1)
)
# Use walk2() to make histograms with the right breaks
walk2(sims, breaks_list, hist)
An extension of these hard coded break values for the bins, would be to use a function to calculate them whenever our data changes.
# Variable rather than hard coded range finder
find_breaks <- function(x){
rng <- range(x, na.rm = TRUE)
seq(rng[1], rng[2], length.out = 30)
}
# Call find_breaks() on sims[[1]]
find_breaks(sims[[1]])## [1] 7.859287 7.995212 8.131137 8.267062 8.402987 8.538912 8.674837
## [8] 8.810762 8.946687 9.082612 9.218537 9.354462 9.490387 9.626312
## [15] 9.762237 9.898162 10.034087 10.170012 10.305937 10.441862 10.577787
## [22] 10.713712 10.849637 10.985562 11.121487 11.257412 11.393337 11.529262
## [29] 11.665187 11.801112We can now use these breaks for our histograms.
# Use map() to iterate find_breaks() over sims: nice_breaks
nice_breaks <- map(sims, find_breaks)
# Use nice_breaks as the second argument to walk2()
walk2(sims, nice_breaks, hist)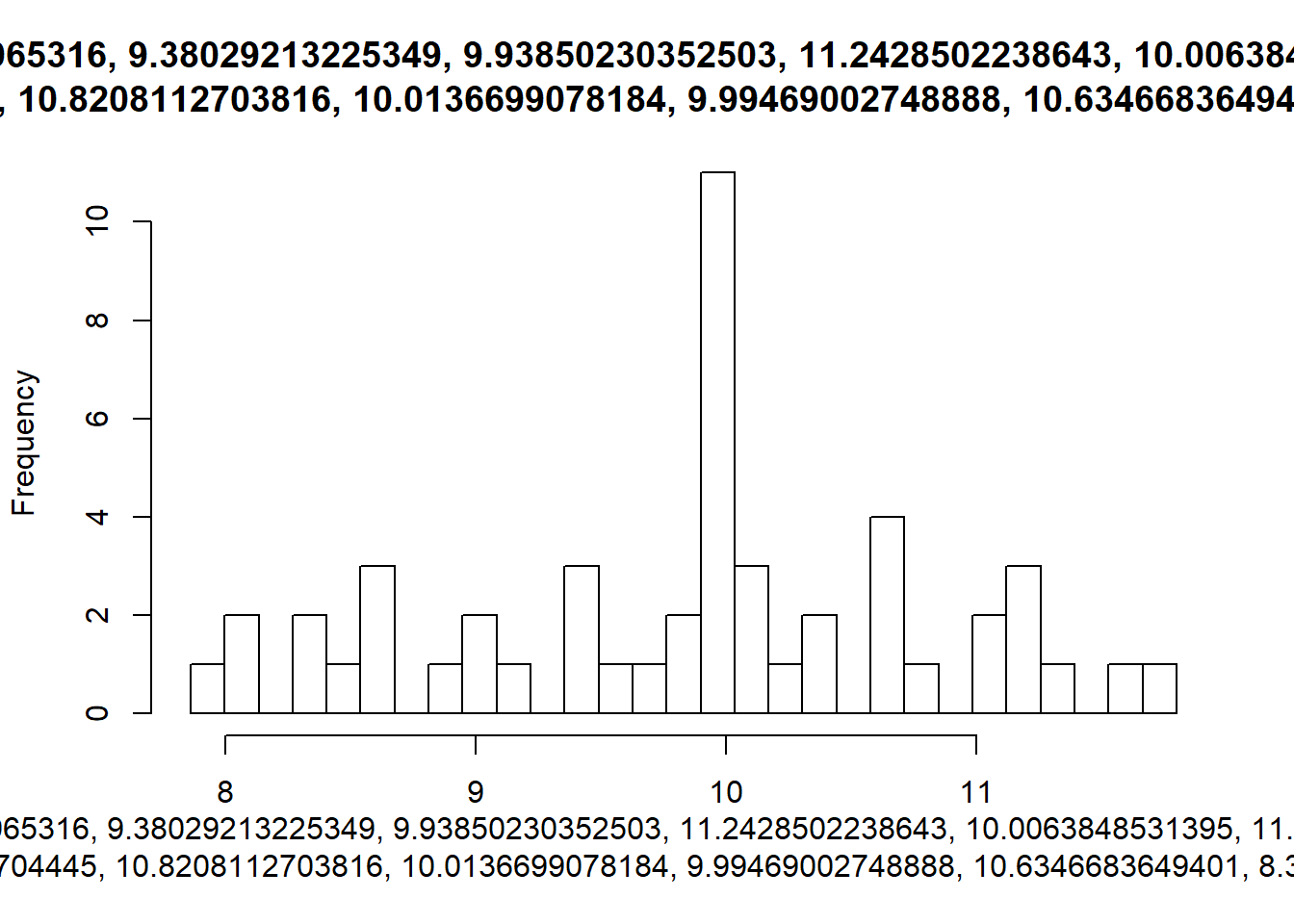
Next we want to tidy the labels. We can use the … argument to any of the map() or walk() functions to pass in further arguments to the function .f. In this case, we might decide we don’t want any labels on the x-axis, in which case we need to pass an empty string to the xlab argument of hist():
walk2(sims, nice_breaks, hist, xlab = “”)
For the titles, we don’t want them to be the same for each plot. How can we iterate over the arguments x, breaks and main? There is a pwalk() function that works just like pmap().
Note that in the following example, xlab = “” is kept outside of the list of arguments being iterated over since it’s the same value for all three histograms.
# Increase sample size to 1000
sims <- invoke_map(f, params, n = 1000)
# Compute nice_breaks (don't change this)
nice_breaks <- map(sims, find_breaks)
# Create a vector nice_titles
nice_titles <- list(
"Normal(10, 1)",
"Uniform(0, 5)",
"Exp(5)"
)
# Use pwalk() instead of walk2()
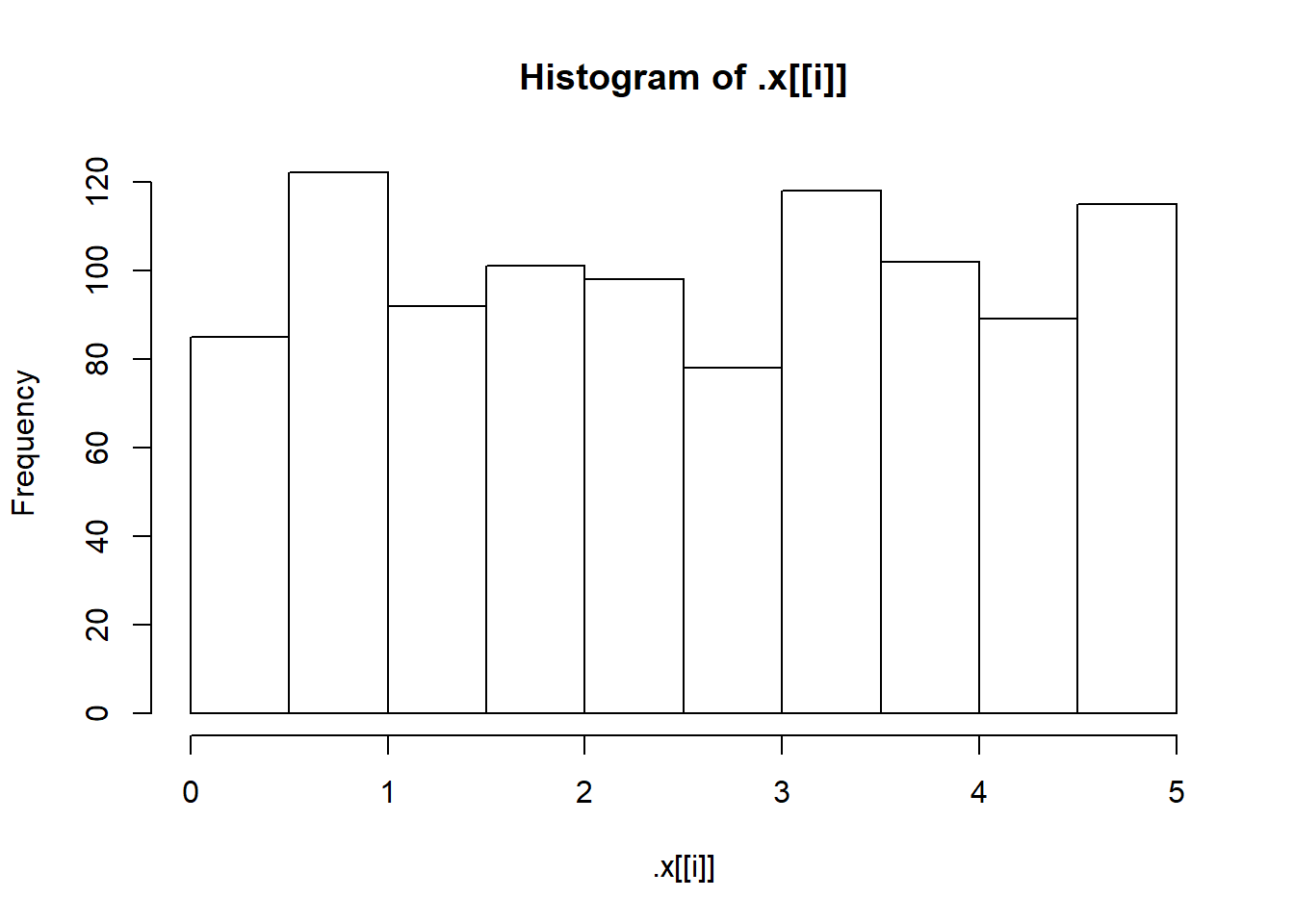
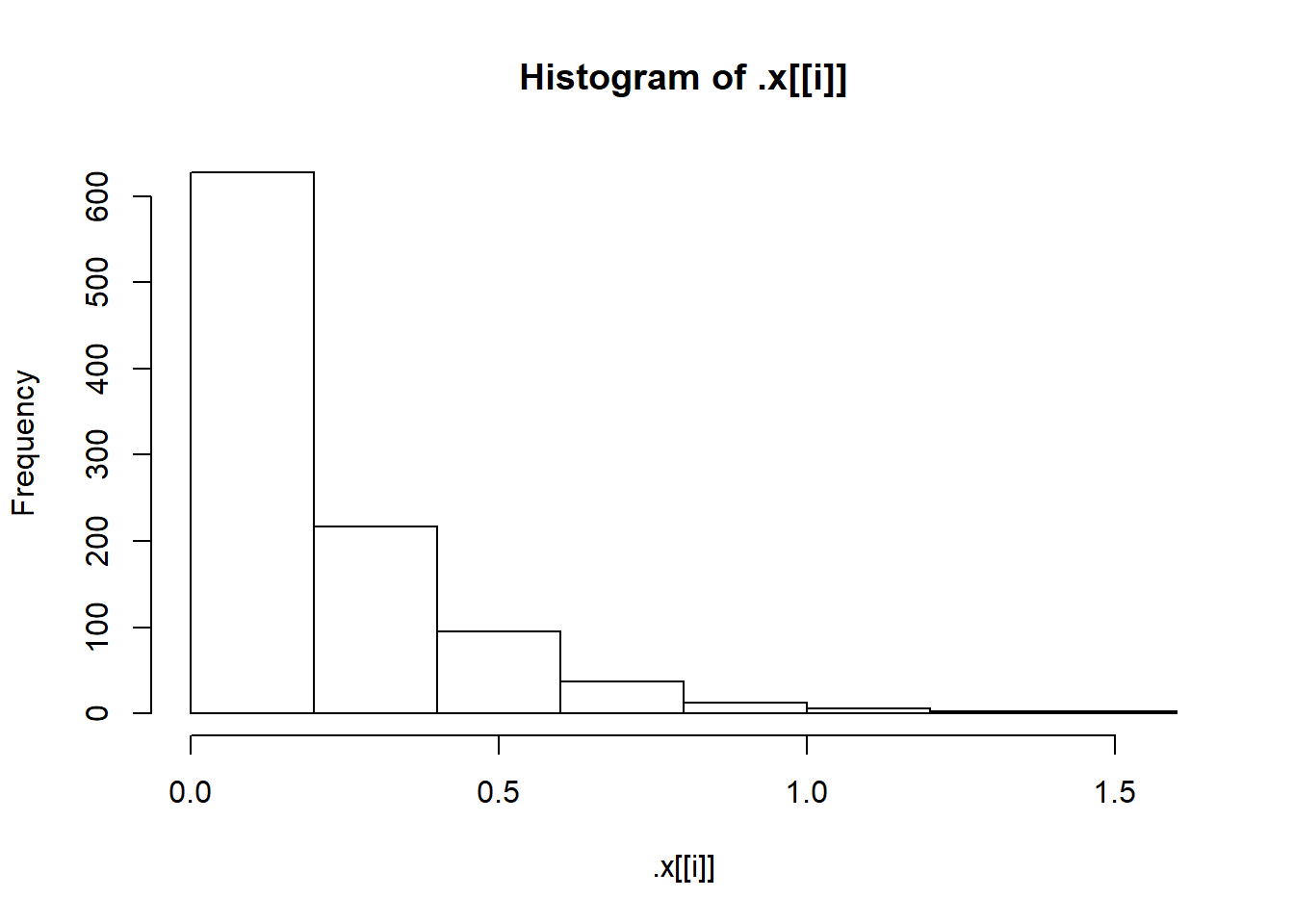
pwalk(list(x = sims, breaks = nice_breaks, main = nice_titles), hist, xlab = "")
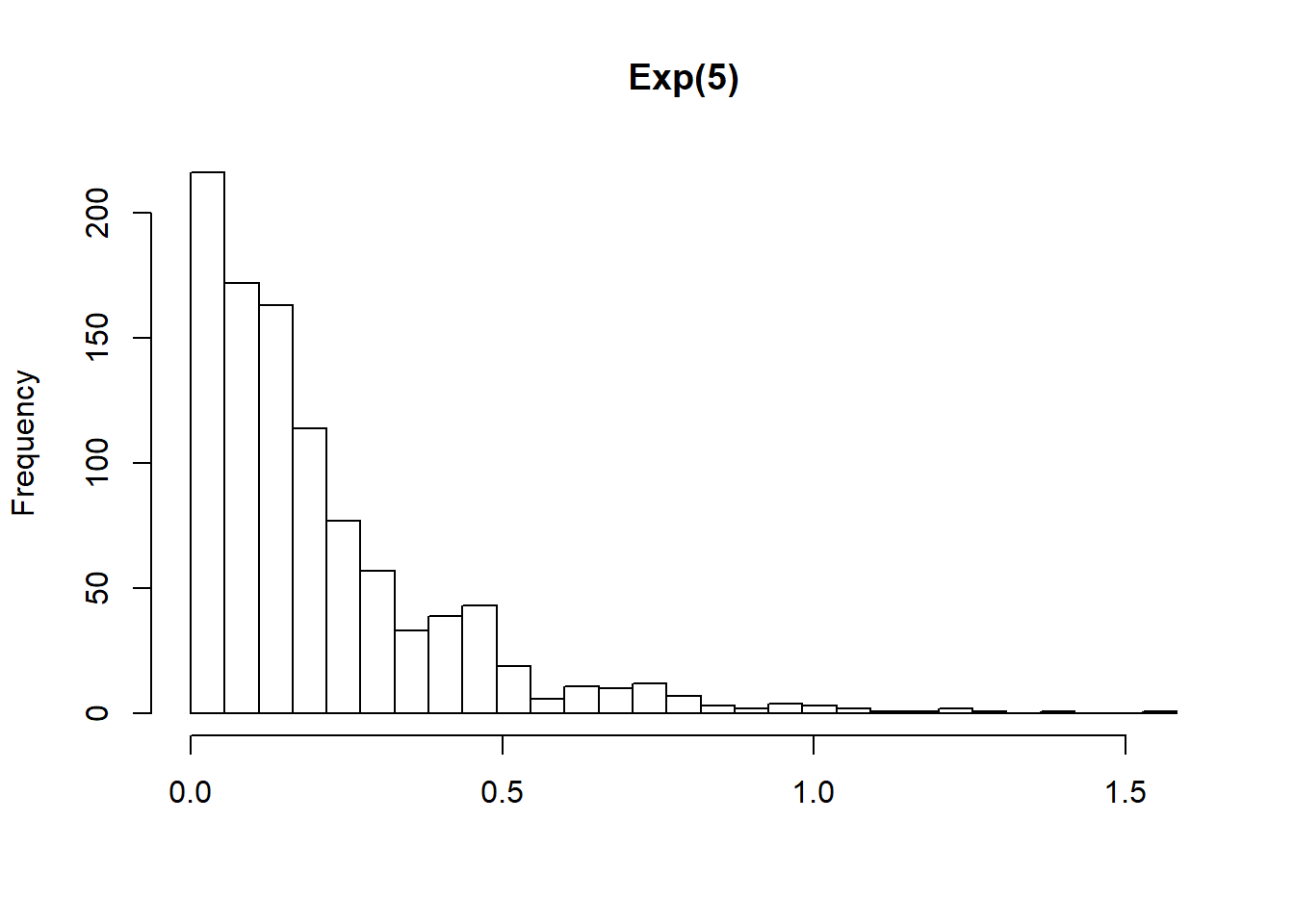
One of the nice things about the walk() functions is that they return the object you passed to them. This means they can easily be used in pipelines (a pipeline is just a short way of saying “a statement with lots of pipes”). WE can, for instance, calculate summary statistics as shown below.
# Pipe this along to map(), using summary() as .f
sims %>%
walk(hist) %>%
map(summary)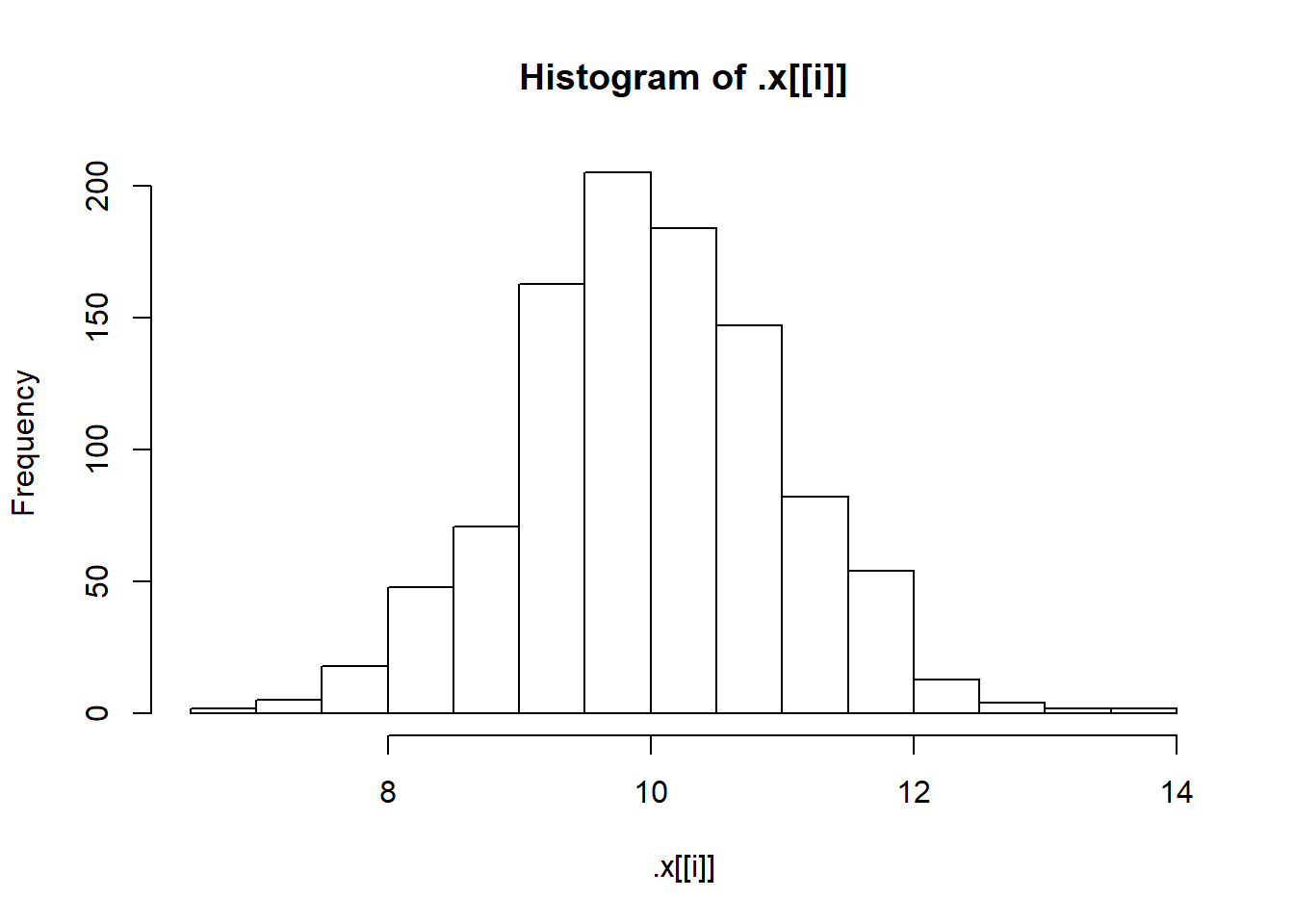
## $Normal
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 6.544 9.387 9.972 10.010 10.684 13.890
##
## $Uniform
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.000235 1.230563 2.507549 2.525777 3.772409 4.999888
##
## $Exp
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0001179 0.0636020 0.1467002 0.2097436 0.2804284 1.58123533.5 Robust Functions
Robust functions either work or give error messages that can be understood. R is both an interactive analytical environment (helpful) and programming environment (strict). Interactive functions are designed to iterate over things quickly to help with analysis, the programming/robust functions on the other hand want to get things right. Interactive functions try to guess at the type of things you want to achieve, which can cause problems later on. There are 3 main types of problem functions:
- TYpe-unstable functions - they return different types of things. For example, with one type of input they might return a vector, but with another type they return a dataframe or a matrix.
- Non standard evaluation - ‘an important part of R’s magic’ says Hadley. It allows you to use succinct APIs like ggplot and dpylr, but it can introduce ambiguity when programming
- Hidden arguments - R has global options that can affect the operation of some functions. The most notorious of these are strings as factors.
# Define troublesome x and y
x <- c(NA, NA, NA)
y <- c( 1, NA, NA, NA)
both_na <- function(x, y) {
# Add stopifnot() to check length of x and y
stopifnot(length(x) == length(y))
sum(is.na(x) & is.na(y))
}
# Call both_na() on x and y
both_na(x, y)We might want a more informative error message. To do so, we use the stop() rather than the stopifnot() function, which has more options including specifying the error message.
# Define troublesome x and y
x <- c(NA, NA, NA)
y <- c( 1, NA, NA, NA)
both_na <- function(x, y) {
if (length(x) != length(y)) {
stop("x and y must have the same length", call. = FALSE)
}
sum(is.na(x) & is.na(y))
}
# Call both_na()
both_na(x, y)3.5.1 Unstable types
An unstable type is a function whose output can’t be known without being fully aware of what it’s inputs are. They can be hard to program with, since you need to write cases which handle all the different input types. Most of the time this doesn’t matter, but problems can arise when type inconsistent functions are burried within your own functions.
Where possible you should try to avoid writing type unstable functions. The first step in this is to avoid using such functions inside your own functions, which comes from knowing what the common type-inconsistent functions are e.g. sapply. You also need to know a set of type consistent functions that can be used, which include those from the purrr package.
3.5.2 Non standard evaluation (NSE)
These are functions that don’t use the usual lookup rules. One example is the subset function, which takes a dataset then a control function, such as disp > 400, to subset the data e.g. subset(mtcars, disp > 400). Because disp only exists within the mtcars data frame, we can only evaluation disp > 400 inside the mtcars data, not in the global environment. Non standard evaulation functions are great as they can save a lot of typing, but they can cause problems inside your own functions.
Another example of NSE is within ggplot, where we can call a data frame initially, but don’t have to apply the $ sign notation for all the aesthetic mappings within the ggplot call, we only need to specify the data frame once. Dplyr also has a number of NSE functions. BUT these functions can call objects from the global enironment also, for instance a grid search / control object or vector for ML can be called within a model (e.g. caret package). These speed benefits can make programming with such functions difficult.
To get around NSE, you can avoid using them in your own functions, or try to protect against where they cause problems. As within unstable types, the majority of the time (95%) such things may not cause problems and it is the edge cases we need to be aware of.
More information is available in Hadley’s NSE vignette.
For example, if we had the following NSE function (filter from dplyr) within our own function
big_x <- function(df, threshold) { dplyr::filter(df, x > threshold) }
There are two ways this could fail
- The x column doesn’t exist in df - but may exist in the global environment, causing the function to find a value there
- There is a threshold column in df - causing dplyr to look inside the dataframe first and finding the incorrect value, rather our desired value as an argument to the custom/user defined function.
We could we write our function previously outlined with stop controls to handle these two instances.
big_x <- function(df, threshold) {
# Write a check for x not being in df
if (!"x" %in% names(df)) {
stop("df must contain variable called x", call. = FALSE)
}
# Write a check for threshold being in df
if ("threshold" %in% names(df)) {
stop("df must not contain variable called threshold", call. = FALSE)
}
dplyr::filter(df, x > threshold)
}